Thinking about identifier and unAPI
This topic is brought up again in gcs-pcs list, the question is whether to use unapi&id=xxx or unapi&uri=xxx. So many smart people have spent quite some time on the topic of identifier, I won't pretend I know what I am talking about ;-) but just some personal thought.
First I think whether an identifier is persistent: horizontal (time) or vertical (across different applications) is really an economic issue. There are really three categories: precious, normal, or free one.
Sometimes the "thing" is so precious, so people takes extra care, such as DOI, ISBN, handle, PURL, or info URI, another example is the w3c's tech reports always reside in same place. All these needs central control and special care ($$$) are taken.
In second category, we do care but it doesn't worth the extra effort, good examples are such as tag URI, Permanent Link of blog, or various unregistered URIs, people is using them everyday and it works.
The third category is most common URLs, we put it there just because it's resolvable at certain time. There is no guarantee that it will be ever be available tomorrow, and we all live well with this.
My point is that all these identifiers have good reason to exist, and which one to choose is essentially an economic model. And we cannot predict which one will fly and market will tell us.
Now come back to unAPI, I think URI is essentially important because it's cornerstone of the Web, the whole RDF thing is based on URI, we just cannot easily discard it. Second, perhaps weak argument is that using URI will make people think twice before putting something there, therefore help persistence and re-use.
The beauty of URI perhaps can be demonstrated by following example: in blog world people uses "Permanent Link", we can easily plug unapi to blogspace by doing:
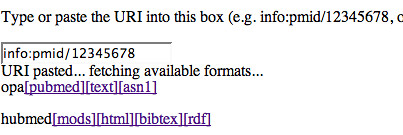
unapi?uri=http://www.inkdroid.org/journal/2006/02/24/hit-sh/&format=dc
unapi?uri=http://www.inkdroid.org/journal/2006/02/24/hit-sh/&format=html
This is really cool because we suddenly have access to rich metadata for all web information. Perhaps people will argue that "http://www.inkdroid.org/journal/2006/02/24/hit-sh/" is not permanent -- again, this is an economic issue, and it perhaps is more persistent than handle ;-)
The last thing is about what copy/paste means in unAPI. One camp said we are copying unapi/?uri, andother camp said that we are copying uri.
Although initially perhaps unapi/?uri is feasible, I think the final goal is to be able to copy/paste uri. I guess this is perhaps Dan's original vision: there are really two parts in unapi, a microformat to specify URI; and a mechanism of accessing them. I seriously think the first part is very important and independent.
Now about second part, it's really building a way of specifying possible services to an URI, and responses format of these services. This excites me a lot. We all know REST model, however REST model only specifies request, it doesn't say anything about
response. However, if unAPI is really successful, it actually adds another aspect to REST. So if I am not mistaken, I saw a huge potential of integrating library with the web.